C/C++: Why can't I return a pointer to a local variable? (An indulgent over-explanation)
Introduction
I want to write a function that returns a pointer to one of its local variables … for some reason. Don’t ask why, it’s a free country. But I can’t do this. Why?
I’ve seen this raised a few times in a few places, but responses tend to be pretty blunt. Basically, you can’t … Or can you? Sometimes you can … for a bit. But, then everything suddenly stops working minutes or, even hours, later.
Some people even pose this question alongside hard screen-shot evidence that it works for them.
Many answers will waffle a little bit about the stack and memory corruption, but none of them go on for pages and pages with loads of painstakingly drawn diagrams describing the process a CPU goes through when calling functions to illustrate why this is bad .. until now.
So, here it is. A lengthy, overindulgent explanation about why you can’t return a local variable pointer from one of your functions. Or, rather, why you can, but it generally won’t work properly. Or if it does, it won’t work properly for long. You might get away with it for a fifty-line University exercise, but not really anywhere else.
An Example
Basically, when I say return a pointer to a local variable I’m talking about a function like this:
1
2
3
4
5
6
7
8
#include <stdio.h>
int* getNumberFromUser() {
int n;
printf("Enter a number: ");
scanf("%d\n",&n);
return &n;
}
This function reads a value from the user into variable n and returns a pointer to that variable, instead of the variable itself. You might be looking at this and wondering Why on earth would anyone want to do that? Well they probably wouldn’t because this is a simple and stupid example, but the reason why this particular function won’t work is the same reason why much more complex ones won’t work.
Either way, we’ll start with a couple of core concepts to get the ball rolling.
Memory
Memory (or RAM) is really just a long list of bits that can be set to 1 or 0 and, in modern computing, it’s a very, very long list of bits. For instance, my home laptop has 32-GB of RAM which is 274,877,906,944 bits, or two hundred seventy-four billion, eight hundred seventy-seven million, nine hundred six thousand, nine hundred forty-four bits.
This list of bits is logically delineated into sections by our software and these sections are used to store artifacts required for it to function. These artifacts could be image data for a computer game sprite, a text block being edited for a word-processor, or a bunch of C++ objects used to run our operating system. Anything at all.
In order to provide access to these objects, an address is assigned to every eight bits (or one byte) of memory. Addresses begin at 0 and end at the final 8 bits of RAM. This is a round-about way of saying that memory is indexed by byte. When an object is stored in memory, it must always start aligned to an addressable byte. To retrieve an object from memory, you then simply need to know the address of its first byte, and how big it is.
Functions
Functions exist in binary code, too, it’s just their level of abstraction is a lot lower - almost non-existent. They’re not delineated with a keyword or token that identifies them as a function, for instance, they’re just blocks of instructions buried among the many other instructions that make up your program somewhere in one of those sections of memory I mentioned above.
Functions are identified purely by the address of their first instruction and executed when the CPU instruction pointer is updated to point at that address, usually using the CALL instruction or one of the many variations of the JMP instruction. Passing parameters is achieved through any mechanism you want, if you’re programming at that level, but if you want your program to play nice with its operating system’s API you would stick to a documented ABI (or Application Binary Interface) which stipulates (among other things) how this should be done. For instance, Windows 64-bit states that the first four non-floating point parameters to each function should be loaded into CPU registers RCX, RDX, R8 and R9 with any remaining parameters pushed to the stack. Windows API functions just assume those parameters are available in those locations when their called - or rather, when the CPU jumps to the address of the section of code designated as that particular OS function.
The Stack
The stack is another section of of memory reserved for local function data. It’s split into stack-frames. A stack-frame is just a fancy name for a sub-section of the stack that’s reserved for a function’s private use. While operating systems like Windows and Linux expect the stack-frame to be partitioned in a certain way, this partitioning is abstract. Physically, its just space in memory - another section of bytes. Of course, if you ignore your operating system’s specification of a stack-frame entirely, your program will almost certainly crash if it tries to call anything in the OS’s API.
In 64-bit computing, the stack-pointer CPU register (or RSP for Intel 64-bit CPUs) always stores the address of the current stack-frame. That is, the stack-frame belonging to the current function or sub-routine being executed by the CPU. Items in the stack-frame are accessed using offsets from this address.
When a program starts, the stack-pointer is initialised with an address that, in theory, could be anywhere in memory, but is usually higher up. In these cases, the Stack grows down, so when items are added, their memory addresses decrease, which can be confusing if you’re debugging and notice the higher up the stack you walk, the lower the address. The reason for this is that the stack must co-exist with the program’s code, static variables and its ‘heap’, or ‘free-store’. The heap, therefore, begins at low memory addresses, after the program code and data, and grows upward as items are added. If the stack and heap addresses clash, then you’ve run out of memory.
Below is yet another one of those diagrams showing the position of the stack and the heap because there aren’t enough of them around, are there? Though this one does have the added value of showing the position of the operating system code and the actual program code with it’s static data variables. These, too, are generally placed at low addresses, even beneath the heap.
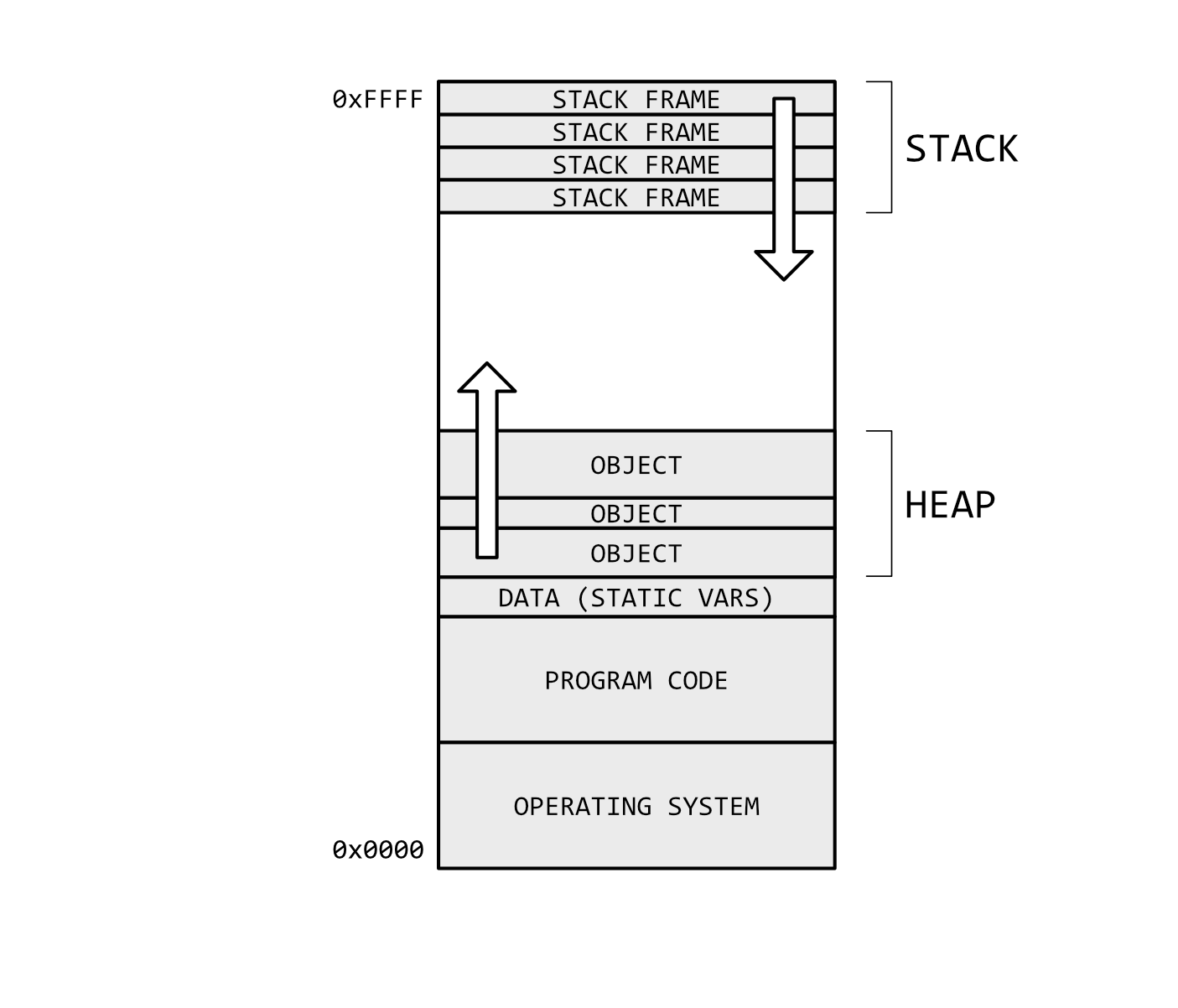 Yet another Heap vs Stack diagram. Marvellous.
Yet another Heap vs Stack diagram. Marvellous.
Our Conceptual machine
To illustrate why we can’t (or rather, shouldn’t) be passing local variable pointers back to our main program we’re going to step through the process of function-calling at a low level, and to help with this I’m going to use a pared-down ‘conceptual’ CPU so we can focus on core concepts without worrying about the rest of the CPU mechanics.
The main features of this CPU are:
Our stack-frames are used to store local variables only, nothing else.
Our CPU has a 16-bit data bus which means it cannot use data larger than 16-bits wide, so the largest positive integer it can handle is 65535 (or 0xFFFF).
Our CPU has a 16-bit address bus which means the it cannot access memory locations with an address higher than 65535 (0xFFFF), so the maximum amount of memory our machine can have is about 65K.
We will show only two CPU registers:
SPwhich is the stack-pointer and always points to the address at the top of the current stack-frame, andRVwhich we will use to store the return values from our functions. Other registers such as data registers and the CPU instruction pointer will be implicit.The machine does not use a virtual memory scheme. While this wouldn’t invalidate the example, it adds a layer of complexity not required.
Steps
Ok, let’s go through each step of the above example program and see what happens. We’re going to assume our program has loaded and begun. We’re also going to assume the program is free to run as it is with no preempting from the Operating System or interrupts.
Step 1 - Program Start
Our program has started and the stack-pointer initialised to the highest address possible on our 16-bit system, 0xFFFF. In reality, it wouldn’t necessarily be the highest address, but it would be a high one.
Note also that we have set the RV (Return Value) register to 0x00 and all other memory data to 0x00. Again, this is unrealistic. Memory is rarely cleared before programs use it. Most of the time detritus from previous use remains. In fact, that is one of the key points of this post.
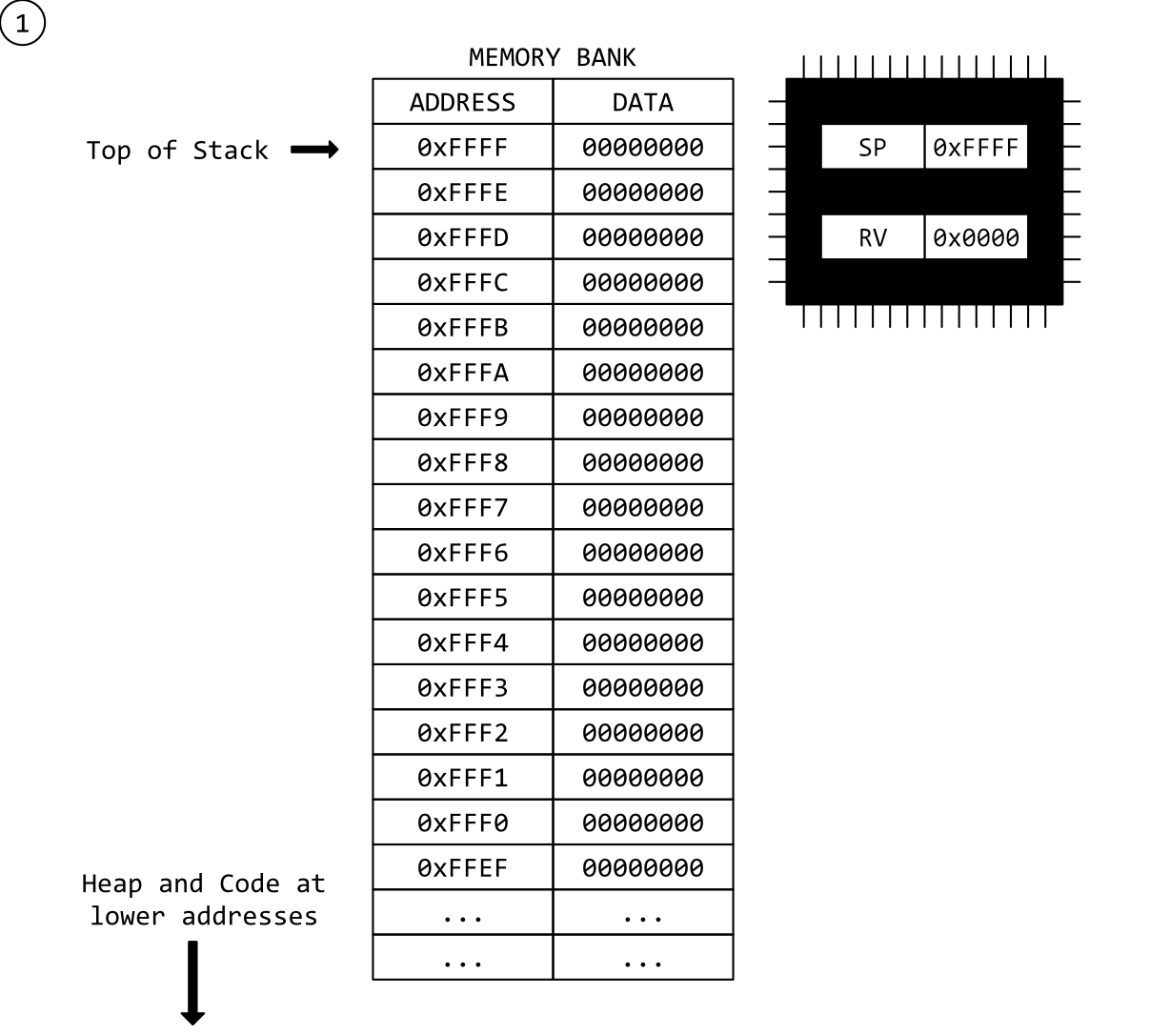 Program Start
Program Start
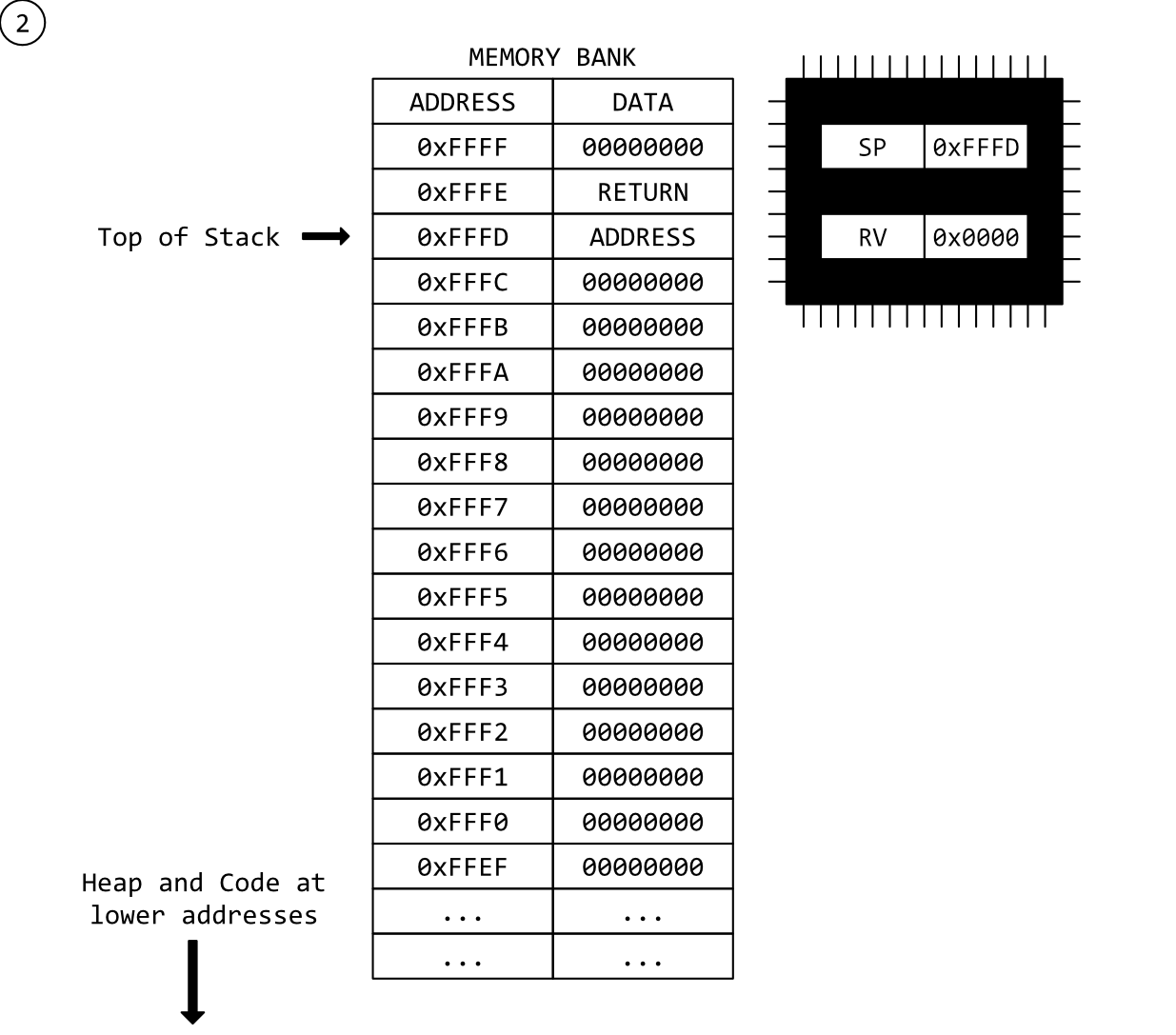
Step 2 - A Function Called
A CALL instruction has been executed. On our machine, the CALL instruction does two things (strangely similar to the Intel CALL instruction):
PUSHes the address of the instruction immediately beneath it onto the top of the stack which also increments the stack-pointer by the size of the address (16-bits). This provides a return location for the CPU once it’s finished executing the function.Inserts the address of the function being called into the CPU’s Instruction Pointer register (referred to as
RIPon a 64-bit Intel, orEIPon 32-bit Intel). This action is not shown on this diagram. It basically ensures the CPU skips to start executing at the function’s address.
Note that the RETURN ADDRESS bytes are loaded in ‘backwards’. The lower-byte of the address is loaded to the high stack address, first, then the higher-byte is loaded into the lower stack address. This is little-endian storage and, again funnily enough, is how Intel stores data into memory.
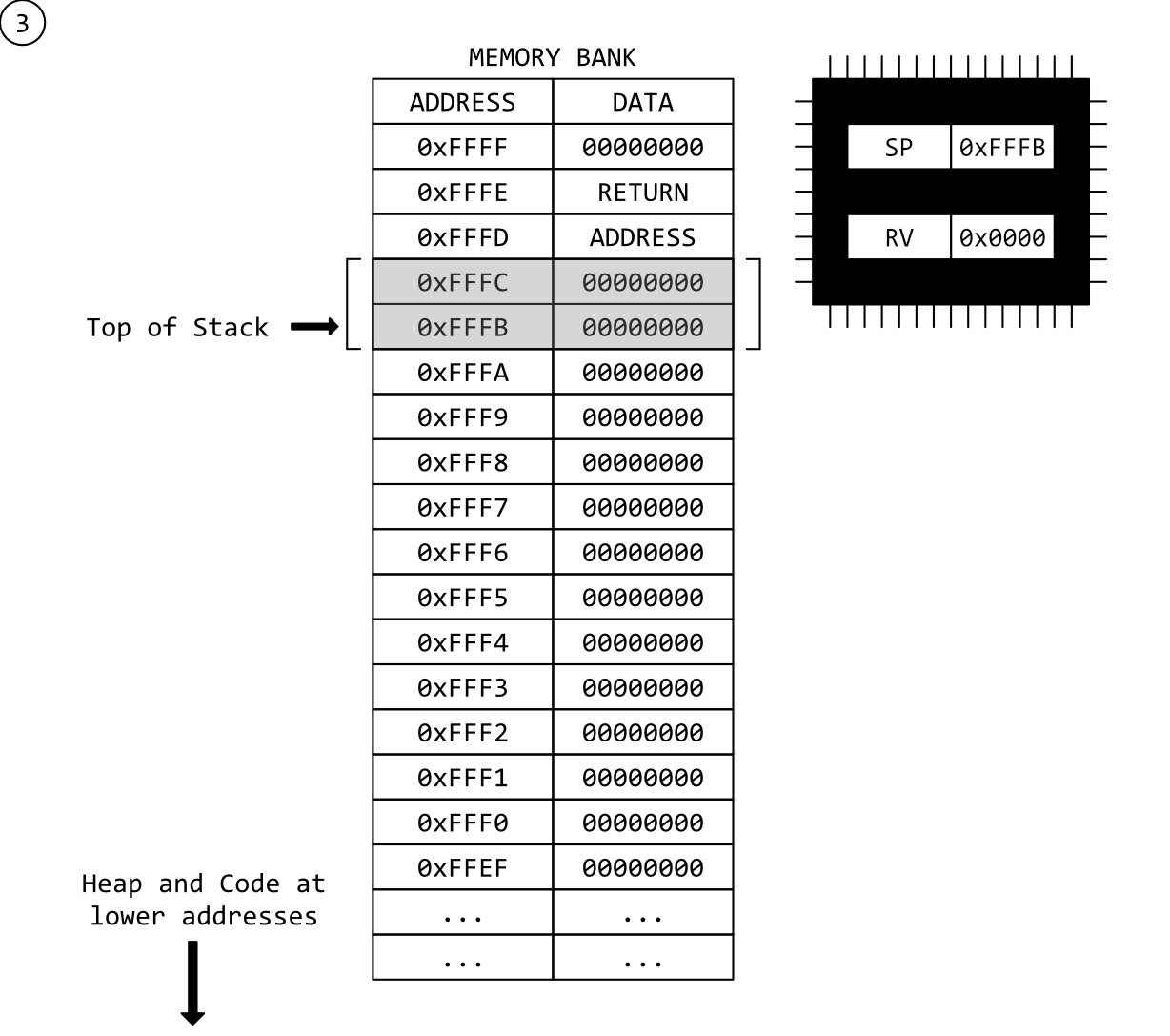
Step 3 - Building our Function’s Stack Frame
When writing our code, we told the compiler that the variable i was an int. The fictional committee that standardises C compilers for our architecture has decided that an int is a 16-bit wide number, meaning anyone who wants to write a C compiler compatible with that standard must translate all int variables into a 16-bit value when compiling.
(In the real-world, the C Standards Committee has decided that an int in C is 32-bits on modern 64-bit architecture. This may sound a bit strange - why not 64-bits? - but it helps to maintain backward compatibility with the huge amounts of software already out there, especially when most of it doesn’t really require particularly large numbers to operate. The C standards committee may change this for future architectures, but not without the potential for breaking a shit-ton of legacy software.)
…Anwyay, it’s these standards that let the compiler calculate how much space is needed on the stack for our local variables.
Back to our machine, and the size of our int types means the space required on the stack for our variable, is two-bytes. What’s more, there is only one variable in the whole function, so total space required to be reserved in our stack-frame is still two bytes.
When the compiler builds our executable, CPU instructions are inserted at the top of our function to subtract two bytes from the value in the stack-pointer register, making room for our function variable and leaving us with our stack frame.
That instruction will look similar to this:
1
SUB SP, 0x10
In assembler, this instruction forms part of the function prologue which, among other things such as preserving non-volatile registers, performs various housekeeping procedures at the beginning of each function. In fact, recognising the pattern of a function prologue is how most disassemblers separate functions.
In the diagram, below, the shaded area is the stack-frame. As you can see, it’s purely abstract. Just two bytes of space.
Step 4 - We Got Your Number
We have called scanf() and the user has input a number for us. That number has been stored in the slot for our i variable in the designated place on the stack-frame. I have highlighted the two-byte value in red because I want to keep track of it through the next steps.
A couple of things to point out as I’ve been a bit cheeky, here.
I’ve skipped over the scanf() function call because if I went through displaying the stack state of every damn function call in this chain we’d be here all day. Who knows how many calls scanf() makes? Fact is, we’re pretending that we’re joining our step just as scanf() has completed and our user’s number is safely stored in our function’s stack.
Eagle-eyes (or pedants, depending on my mood) may have spotted that scanf() is passed a pointer to our local variable i, but (hang on a minute!) our variable is local. Isn’t the point of this post you can’t start passing pointers to local variables around?
Actually, in this case it’s fine because we’re passing a reference to our local variable forward into the stack chain. As long as our function is still live and executing (it hasn’t returned, yet) the variable i is still live and safe. This post is discussing returning local variables from functions, once they’re complete.
That said, I’d argue it’s really not the greatest way of doing things in this day and age, and goes to show how ancient scanf() is.
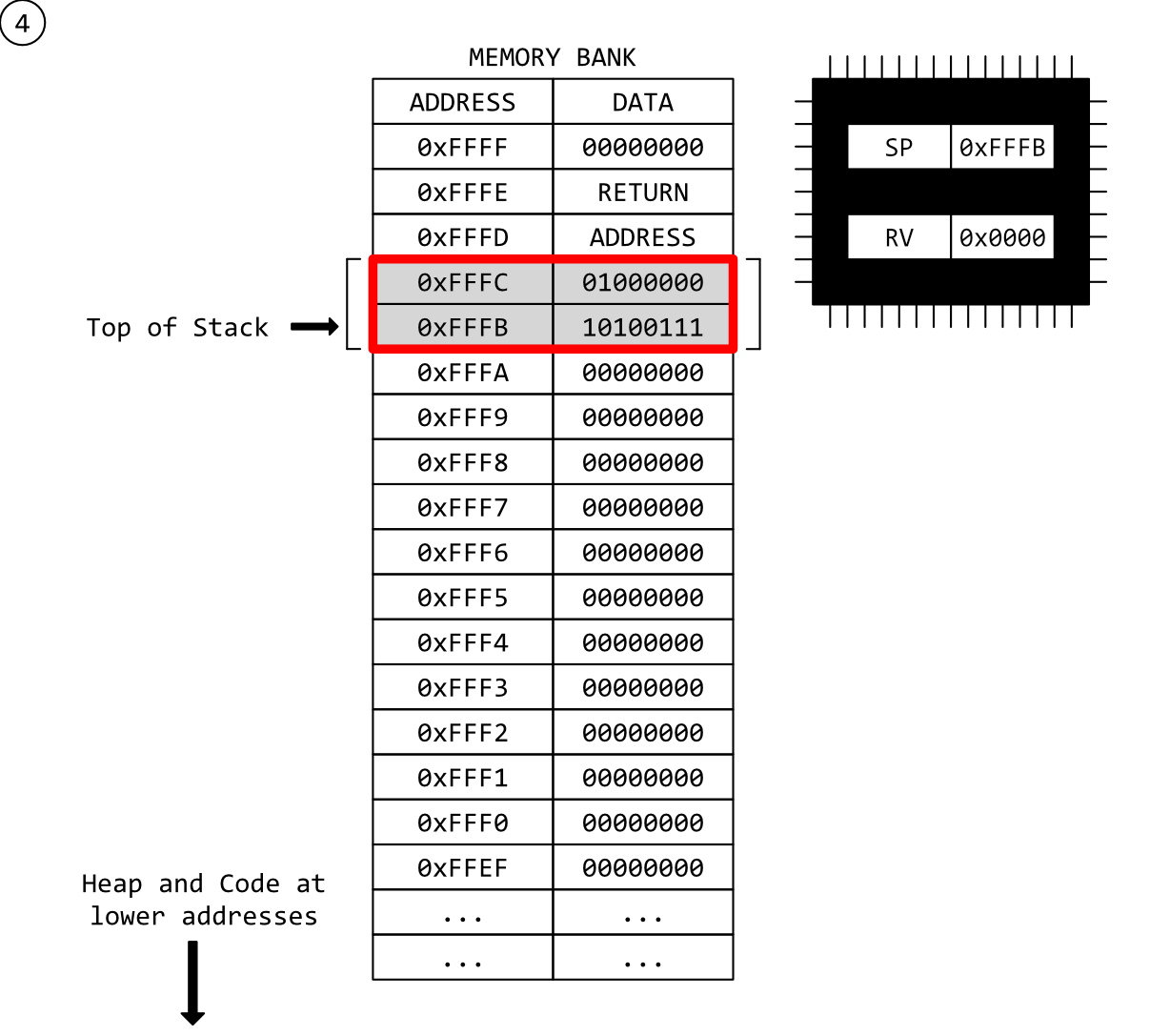
Step 5 - Function Epilogue
In step 3 we talked about a function prologue, a series of instructions that perform a few housekeeping tasks for the CPU before executing the core function. One of those was subtracting the stack-frame size from the SP register to make a stack-frame with enough room for the variables in our function. Well, now our function has completed, it’s time to get rid of the stack-frame in our function epilogue. As you’ve probably guessed, the stack-frame is deleted by adding the same value to the SP register that we subtracted in step 3, so that the top of the stack points back to the return address of the function.
The second thing to note about this step is that the RV (return value) register has been updated with the address of our i variable. This is how the return value (the pointer to i) gets back to the main program - the return &i statement in the source code.
Note that no data has been cleared up. The value loaded into i is still present at its address in the stack.
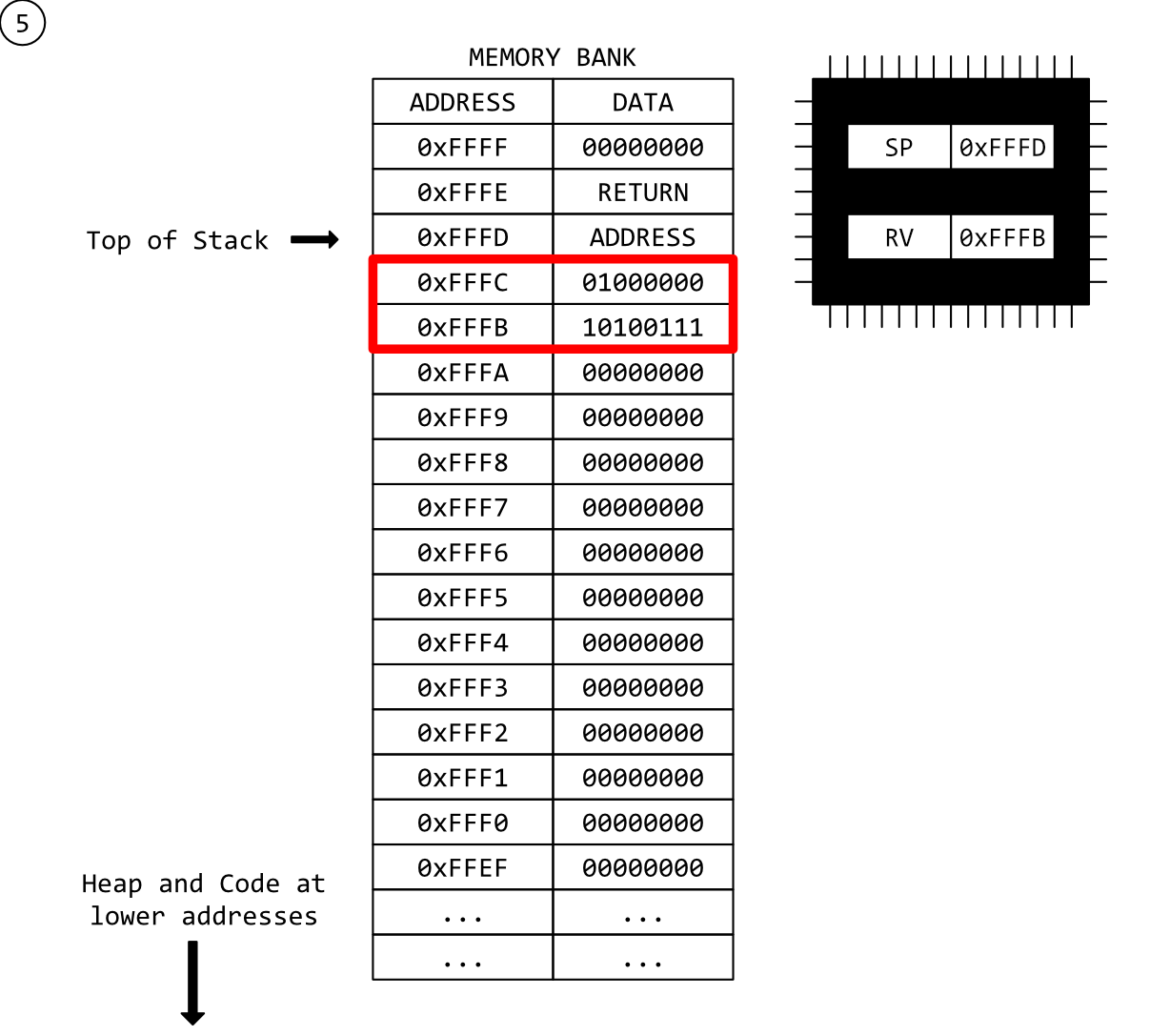
Step 6 - RET
We’ve reached the end of our function. How do we know this? Because RET has been called. If this command wasn’t used to inform the CPU we’re done with this portion of code, it would simply continue into the next instruction. I’m still trying to get across that there is no delineation of functions at this low level, no closing brace or end func token. Just one long list of instructions with JMPs, CALLs and RETs.
RET is the accompanying instruction for CALL. It does the following:
POPs the value (it assumes to be a return address) from the top of the stack and into the CPU’s instruction pointer so that it skips to continue execution at that address. ThePOPinstruction also subtracts the size of the address from theSPregister. The top of our stack is now back to where it was at the start of the program.…that’s it.
This time, the instruction inserted by the compiler will look like this:
1
ADD SP, 0x10
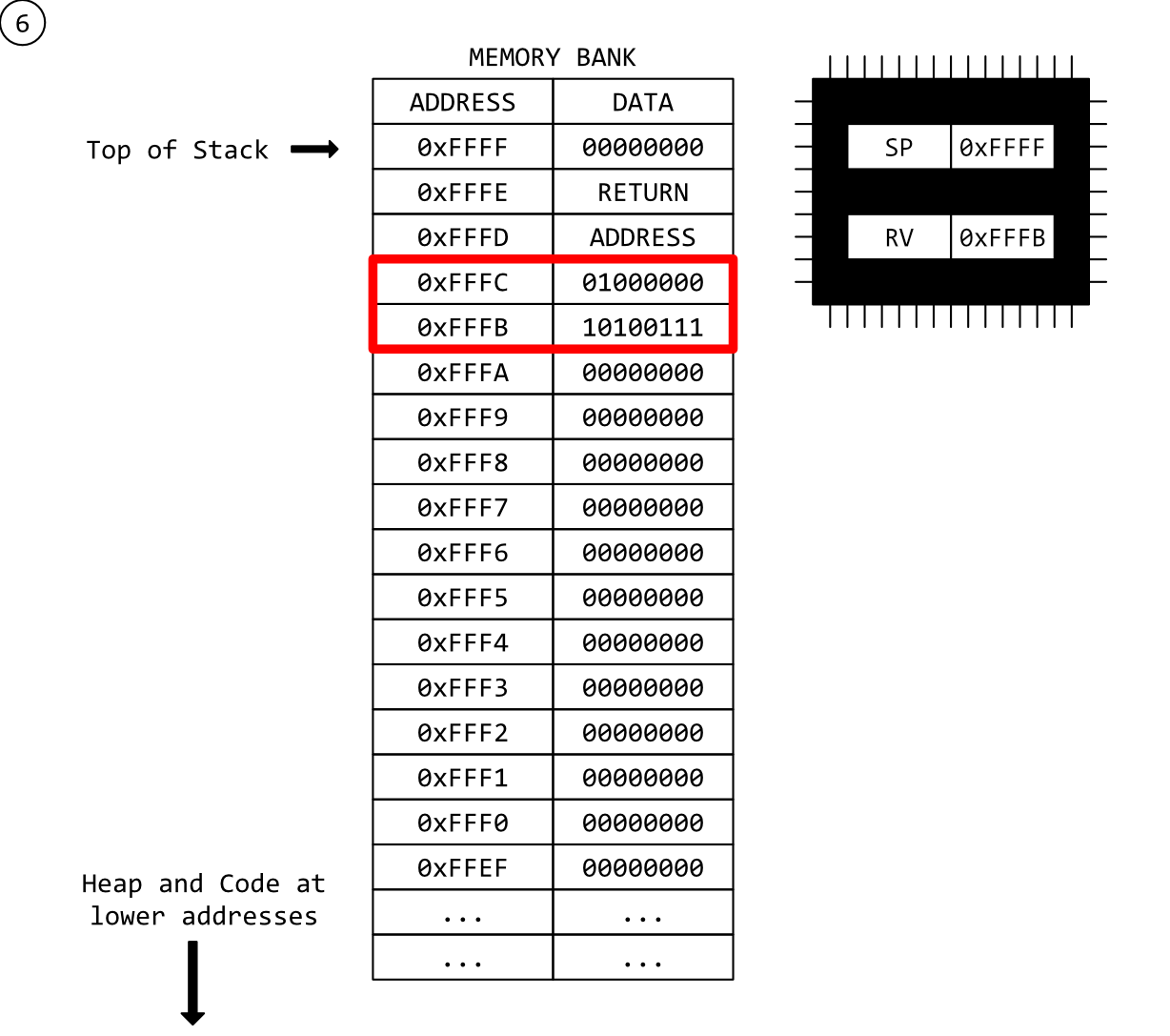
Timeout!
Ok, this is where it gets confusing for people who ask this question based entirely on how they’re seeing their program behave.
We have fully returned from our function and our top-level program code has resumed executing from the return address. The RV register has the address of i and can still happily de-reference it into our expected integer value because the data is still there. Our earlier function is gone, but it’s left everything hanging around in the block of memory we’re using for our stack. It’s entirely possible this value is still there minutes, hours, days later if another function has not yet been called.
…But what happens when another function is called?
Step 7 - Another Function Call!
Now a different function has been called. Once again, a return address has been pushed on to the stack signifying a CALL instruction.
This is where it all starts to fall apart.
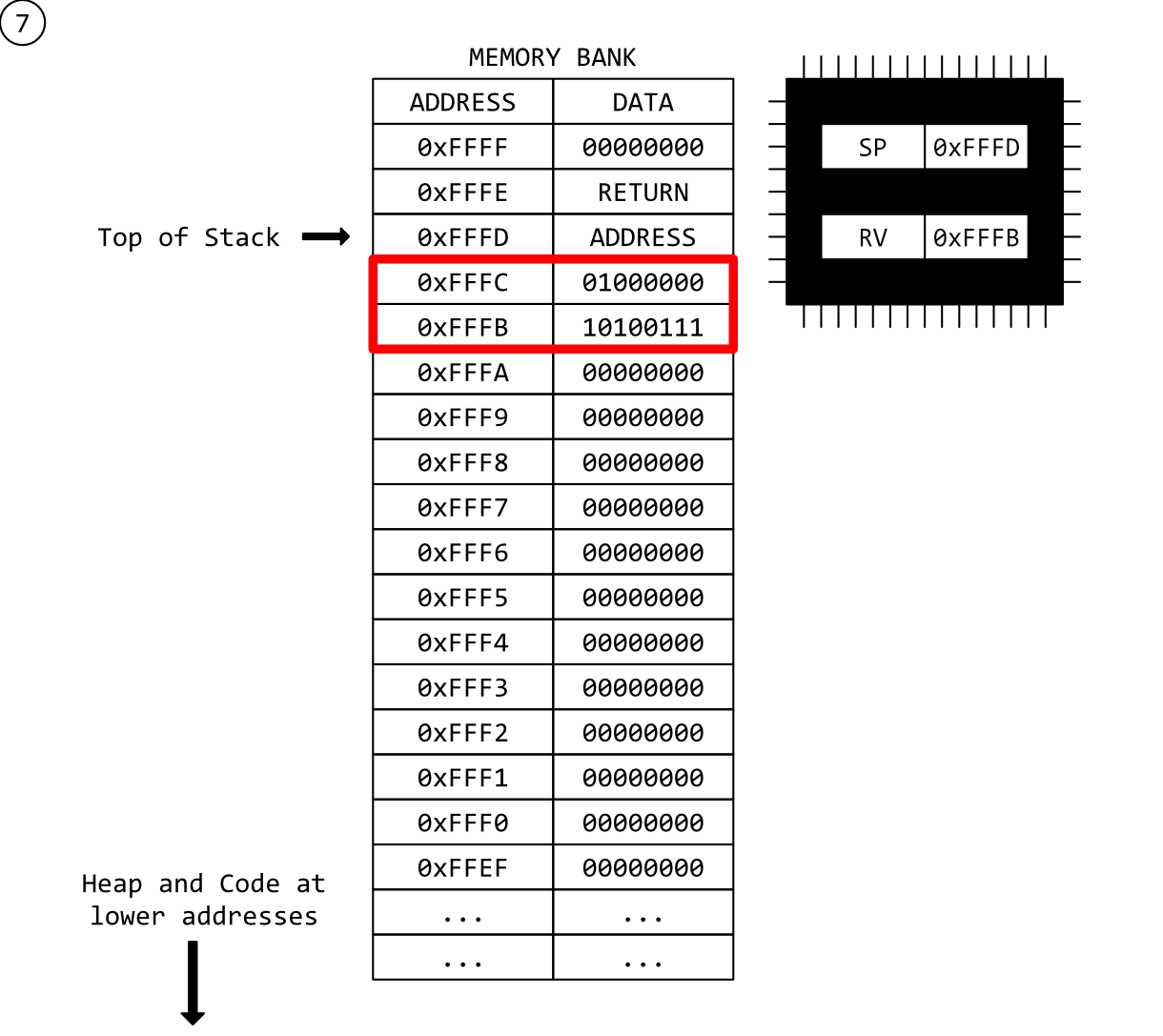
Step 8 - A New Stack Frame
Our new function has designated a new stack-frame. One much larger than our last function. Guess it has larger, or even many more local variables.
Note that the new stack-frame encompasses our old stack frame with our old stack data. Critically, nothing has been overwritten, yet.
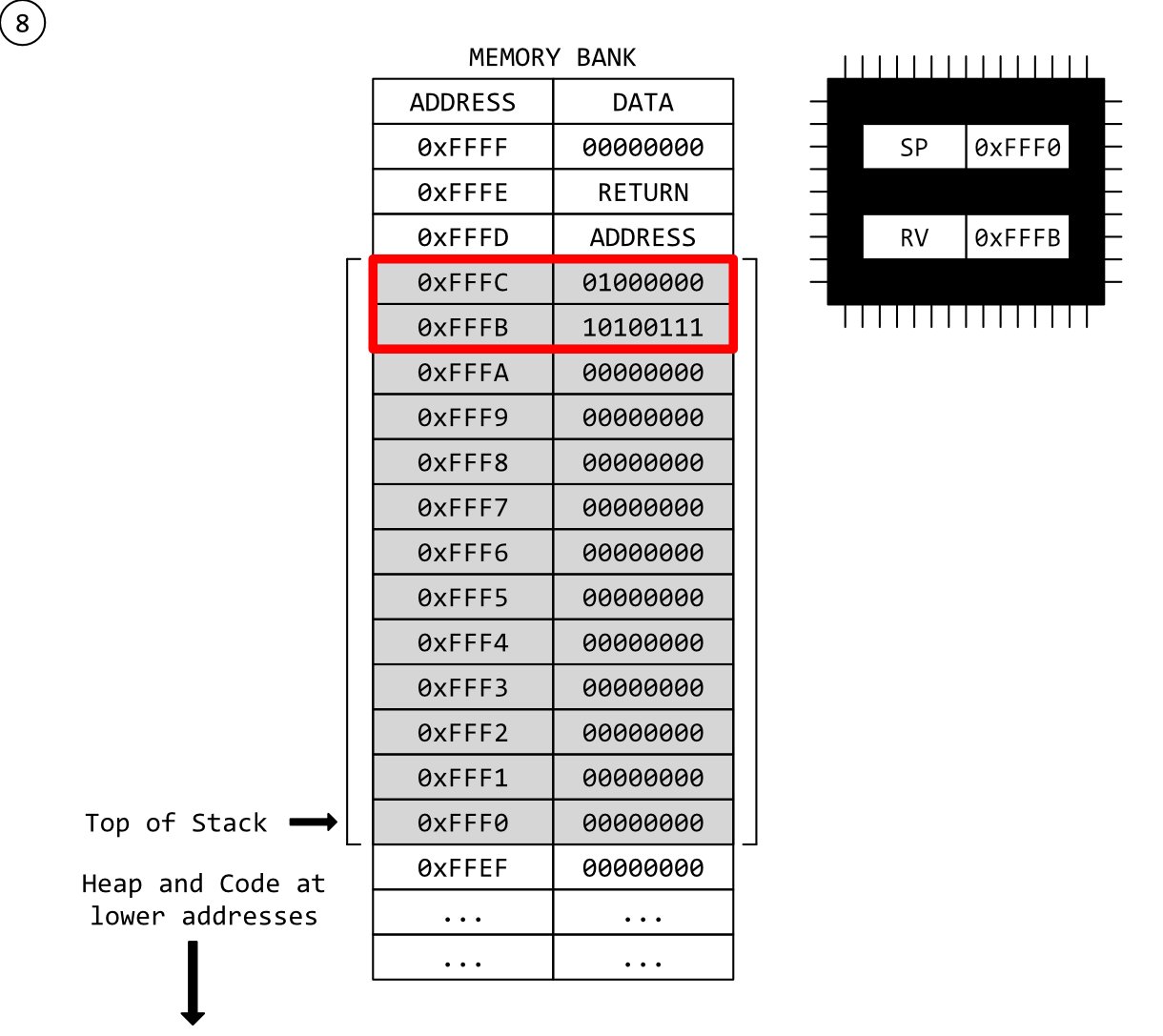
Step 9 - Some New Data
Hopefully, the issue should now be apparent. This new function has its own local variable which seems to be an array of char representing the string, “Hello World!” The last two chars (! and \n) have wiped over our old i variable but, critically, the address for this location is still in our CPU’s RV register. This address now holds a completely different two-bytes!
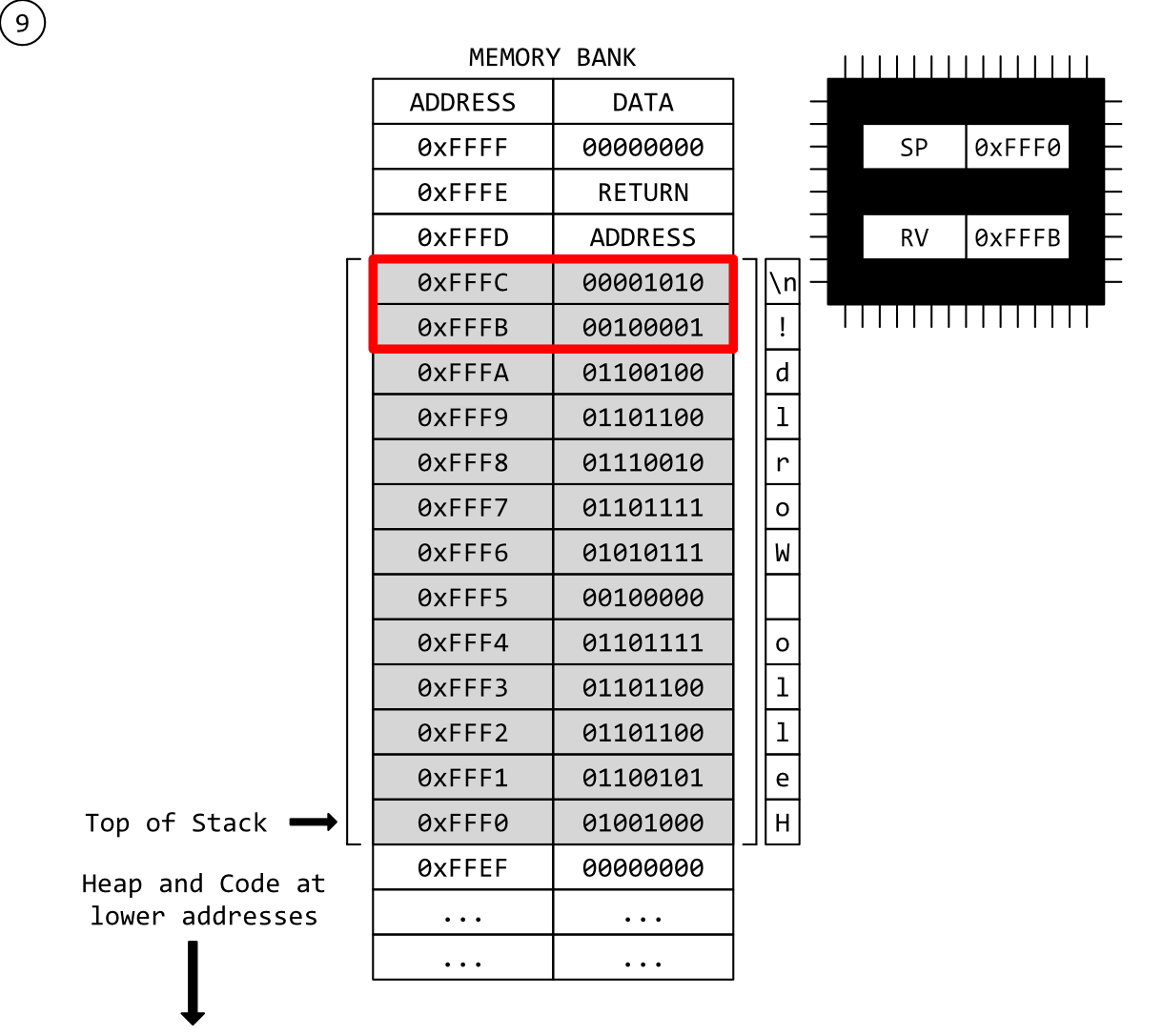
Step 10 - A New Function Epilogue
As with our original function (step 5), our new function is clearing up. It’s reached the end of it’s instructions and is now executing it’s epilogue where it cleans up its stack-frames by adding the original amount subtracted from the SP register back.
Note, again, that no data is cleared.
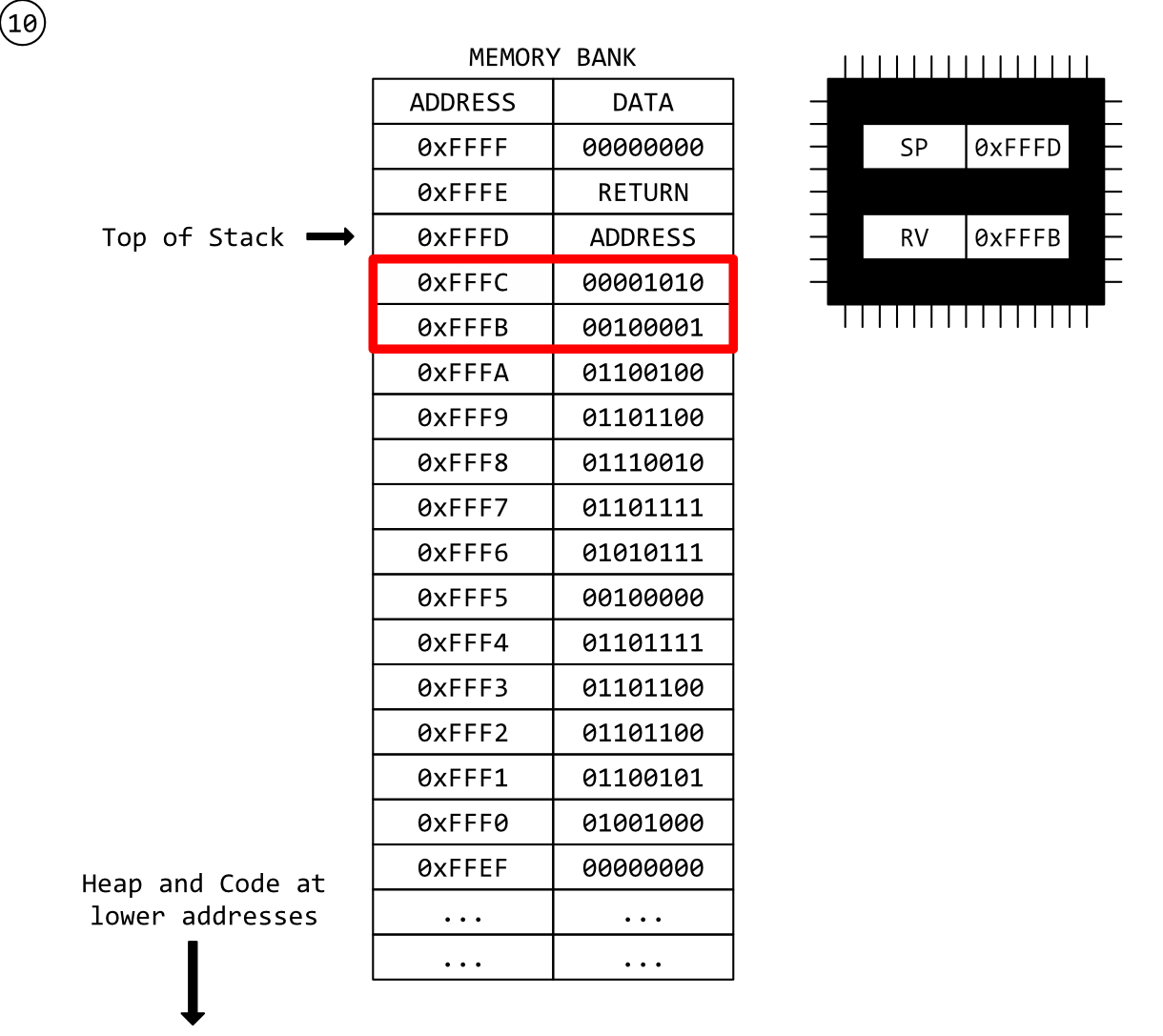
Step 11 - Back to Main
As with step 6, the RET instruction has been executed in our new function which means the new return address has been popped off the stack and into the CPU instruction pointer. The CPU now continues executing our top-level program after the CALL instruction.
Note again that the RV register still holds the address of our old i variable and that there is data at that address, just not the data we loaded into i. Choppy waters ahead.
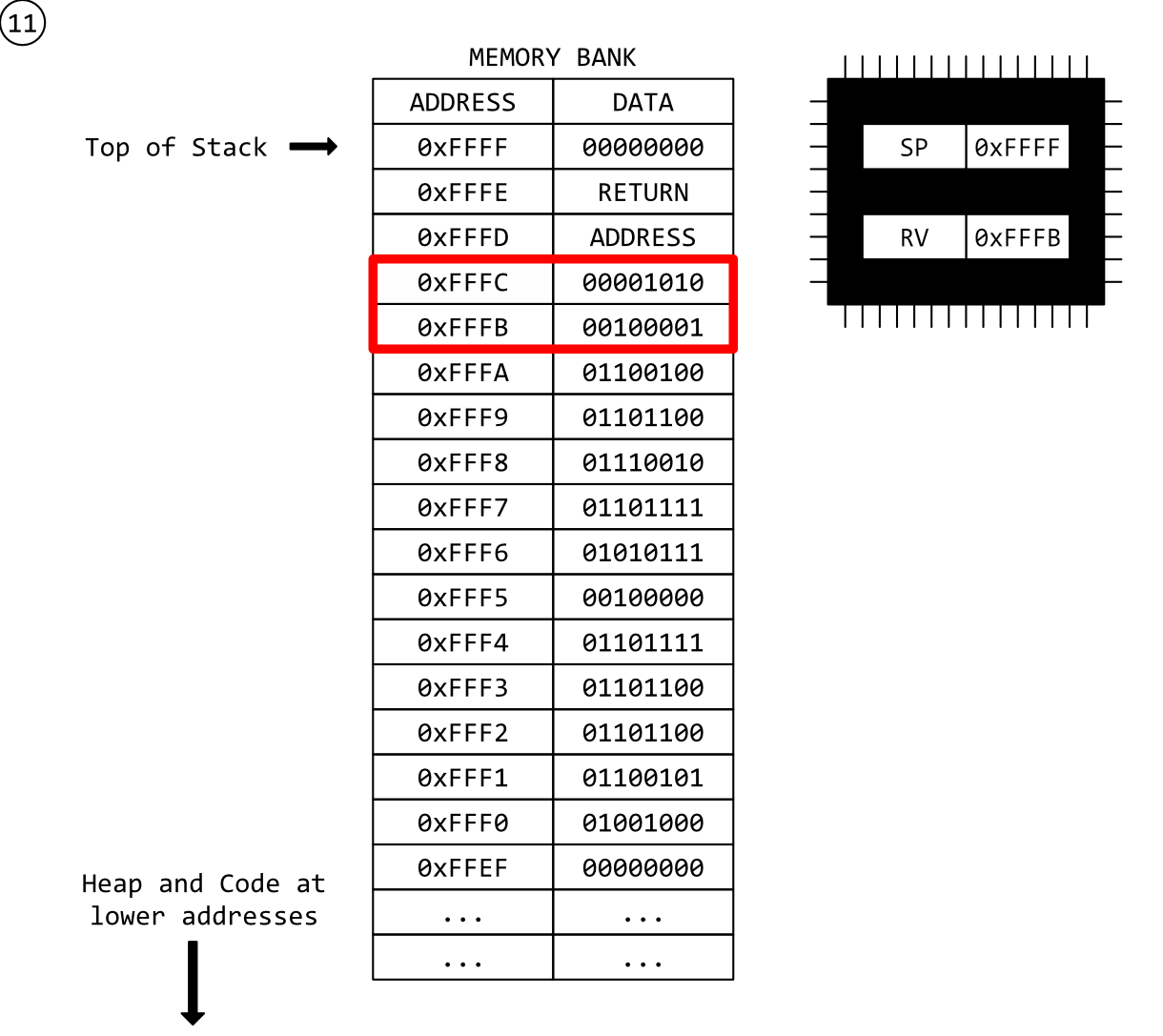
Step 12 - Aaaaaand CRASH! … Eventually
At some point, though you can never be sure when, our top-level program may try to de-reference the address in the RV register, expecting our i value, but will get whatever is now at that address instead. Thing is, this will work and a two-byte value will be retrieved, after all, all data are all just bits at this level, but the program will treat this value as if it was still our i value, and it isn’t.
…But one is an integer and the other is two characters! you might be crying. No, not at all. They’re both just a sequence of bits and when the CPU is told to read two-bytes from the address in RV, it reads two bytes from the address in RV, regardless of how they’re going to be used. Types do not exist at this level, only as abstracts in higher level languages. The CPU will not check those two bytes to make sure they’re a valid value, the programmer must make sure he or she implements any checks required.
The results of this, then, are unpredictable. The value may not translate into anything the program can use and crash it, or, and this is worse in some ways, the program may continue, but do something insane because the value is way out of an expected range.
Conclusion
Yes, there are much simpler two-line answers to this question, but one of the things I enjoy doing is working through these things of a quite, lamp-lit evening with a pen, paper and Affinity Desginer. To draw it out always reveals something else I hadn’t thought of before, even if its relatively minor. For instance, I realised that whenever the stack is initialised, and for subsequent PUSH/POP operations to work in the way Intel describes them, there must have to be an orphaned byte at the top that’s never used. It turns out this is true, but it was something I hadn’t appreciated before and finding it, then understanding it, pleases me.